

This blog post breaks down how agentic RAG works, why it outperforms traditional RAG, and how you can build a secure, production-grade agentic RAG system on top of your private data, step-by-step.
A standard Retrieval-Augmented Generation (RAG) system leverages Large Language Models (LLMs) to retrieve information from private enterprise data. The LLM then summarizes, interprets, or synthesizes that information to answer your query.
But can it deliver a deeper analysis? Can it ask questions like these?:
- Why did our Q3 sales dip in the Northeast, and what patterns connect customer churn to support tickets?
- “Which compliance risks appear across our contracts, and what actions should we take?”
- “What’s driving delays in our supply chain, and how do we fix them?”
The answer is, probably not. Once a question requires multi-step reasoning, cross-source correlation, or actions across multiple data sources, traditional RAGs are no longer sufficient. That’s where agentic RAG shifts the landscape.
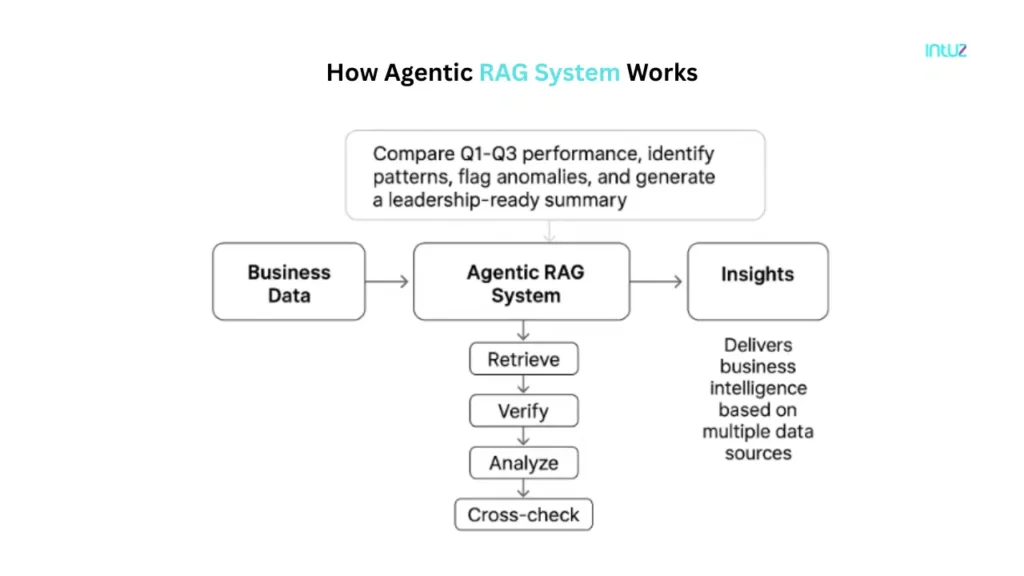
It combines classic retrieval with autonomous agents that can reason, plan, validate, call tools, and execute multi-step workflows. Unlike traditional RAG, which retrieves once and generates once, agentic RAG systems iterate — re-querying, cross-checking, and self-correcting until the answer meets a confidence threshold.
Show
- Traditional RAG fails on multi-step, cross-source enterprise queries — agentic RAG solves this through iterative reasoning and autonomous tool use.
- An agentic RAG system comprises five layers: data ingestion, vector retrieval, LLM, agentic orchestration, and memory/feedback.
- Leading orchestration frameworks include LangChain Agents, LlamaIndex, CrewAI, AutoGen, and LangGraph.
- Enterprise deployment requires RBAC, TLS encryption, prompt-level governance, and compliance mapping (GDPR, HIPAA, SOC 2, ISO 27001).
- Data preparation quality accounts for approximately 80% of downstream retrieval accuracy — it is the single most important implementation factor.
Traditional RAG vs Agentic RAG: Key Differences
| Dimension | Traditional RAG | Agentic RAG |
|---|---|---|
| Processing structure | Single-pass retrieval → answer | Multi-step retrieval → verification → reasoning → synthesis |
| Reasoning depth | Limited reasoning; surface-level responses | Deep reasoning: comparisons, anomaly detection, pattern analysis |
| Validation and quality control | No verification; retrieval errors propagate → higher hallucinations | Agents cross-check, re-retrieve, and self-critique to reduce errors |
| Action and tool use | Cannot call tools or execute actions | Can run tools, calculations, workflows, APIs |
| Use case scope | Direct Q&A only | Complex workflows: reporting, auditing, risk assessment |
| Memory and context management | Stateless; each query is independent | Maintains working memory across steps; can refine results iteratively |
| Autonomy and goal orientation | Purely reactive; waits for a question | Breaks tasks into sub-goals, plans steps, and acts autonomously |
Agentic RAG Architecture: Core Components and Frameworks
Architecture overview
1. Data layer
This is where your enterprise knowledge lives: CRMs, ERPs, BI exports, wikis, PDFs, contracts, support tickets, email threads, and analytics exports. The data is cleaned, structured, chunked, and prepared for embedding. Good data hygiene here determines 80% of downstream accuracy.
In enterprise agentic RAG implementations, data preparation quality accounts for approximately 80% of downstream retrieval accuracy — making ingestion pipeline design the single most important factor in system performance.
2. Retrieval layer
Your processed documents and records are stored inside a vector database, such as Pinecone, FAISS, or Weaviate. Embeddings allow the agentic RAG system to identify semantically relevant information. Metadata filters, like department, data, author, and classification, ensure precision and enforce access rules.
3. LLM layer
The LLM interprets queries, chains reasoning steps, and synthesizes answers. Depending on your compliance, latency, and cost requirements, this could be a managed API (e.g., OpenAI GPT-5.1, Claude, Llama 4) or a private/fine-tuned model hosted in your virtual private cloud.
4. Agentic orchestration layer
This is the upgrade that transforms RAG into agentic RAG. Agentic RAG transforms traditional retrieval from a single-pass lookup into a multi-step reasoning workflow where agents plan, verify, and refine answers before they reach the user. Here, agents:
Here, agents:
- Plan multi-step actions
- Verify retrieved chunks
- Call tools or APIs
- Request additional context
- Break large tasks into sub-tasks
Programming frameworks that power this layer include LangChain Agents, CrewAI, and AutoGen.
5. Memory and feedback layer
Because of this layer, the agentic RAG system learns and refines responses over time:
- Short-term memory holds conversation context
- Long-term memory typically writes validated facts back to the vector store
- Optionally, structured memory, such as relational tables or knowledge graphs, may support richer entity/relationship reasoning
Observability and feedback tooling—for example, Phoenix for tracing/debugging and LangFuse for monitoring, evaluation, and trace logging—detect hallucinations, stale embeddings, or retrieval issues and feed corrective signals back into the pipeline.
Core frameworks for building agentic RAG systems
| Feature | LangChain | LlamaIndex | CrewAI | AutoGen |
|---|---|---|---|---|
| Primary purpose | End-to-end LLM application orchestration | Retrieval-Augmented Generation (RAG) and data indexing | Multi-agent collaboration framework | Multi-agent automation and task execution |
| Core abstraction | Chains, Agents, Tools, Memory | Indexes, Retrievers, Query Engines | Agents with roles + Task orchestration | Agents communicating via messages |
| Vector DB integration | Strong, native integrations with all major DBs | Deep focus on indexing + retrieval | Via LangChain or custom tooling | Manual or via wrappers; less native |
| Prompt management | Templates, parsers, structured outputs | Query pipelines with context injection | Task prompts + persona-based role design | Programmatic prompt passing between agents |
| Agent orchestration | Tool-using agents with ReAct/Plan-and-Execute | Minimal (retrieval only) | Strong multi-agent team coordination | Strong multi-agent messaging workflows |
Did You Know?
- 82% of organisations that successfully converted over half of their GenAI initiatives into production had already adopted an AI platform. (IDC)
- Early enterprise adopters of agentic RAG have reported up to a 40% increase in task automation and faster resolution of knowledge-intensive queries.
- A Forrester report predicts that by 2026, over 60% of enterprises will adopt agent-based AI architectures to boost workflow automation and decision intelligence.
How to Build an Agentic RAG System on Private Enterprise Data: Step-by-Step Implementation
1. Prepare and ingest your data
Start with a simple question: where’s your knowledge stored?
Typical sources include:
- CRMs and ERPs
- BI exports and reports
- PDF contracts, policies, SOPs
- Support tickets and email threads
- Internal wikis and knowledge bases
For each source, decide on the scope, update frequency, and access controls. Then run an Extract, Load, Transform (ELT) pipeline to:
- Extract the content using tools like Unstructured.io, LangChain document loaders, and a custom ETL
- Normalize formats by stripping boilerplate, removing navigation junk, and fixing encoding
- Chunk text into a retrieval-friendly segment, for instance, per section, clause, and paragraph
Pro tip
Before sending any document through your embedding pipeline, run an automated scan to detect Personally Identifiable Information (PII), Payment Card Information (PCI), Protected Health Information (PHI), and other sensitive fields. Redact, mask, or tokenize these elements before generating embeddings so they never enter your vector store.
Insight:
Most enterprises report that data preparation is one of the slowest and most challenging steps when building RAG pipelines. — Capgemini
2. Set up the vector store for retrieval
Once your content is cleaned and chunked, pick a vector database deployment model that aligns with scale, compliance, and ops capabilities.
| Category | Options |
|---|---|
| Managed services | Pinecone, Weaviate Cloud, Milvus Cloud |
| Self-Hosted and library-based | FAISS, Qdrant, pgvector |
Next, generate embeddings by sending your cleaned text to an embedding model (e.g., OpenAI GPT-5.1, Claude, Llama 4, Cohere, or Sentence Transformers), which returns a numeric vector representation for each chunk.
Then upsert embeddings by writing each vector and its associated metadata into your vector database via its “upsert()” or “insert()” API. Lastly, implement retrieval with filters so that only documents matching attributes such as department, region, or role are returned.
Pro tip
Group vectors into single write calls to reduce overhead and speed indexing. Combine semantic search with keyword or BM25 search by running both queries in parallel and merging their scores for better precision on domain-heavy terms.Schedule regular re-indexing by automatically re-embedding updated documents through a cron job or workflow. This will ensure your vector database always reflects the latest content.
3. Integrate the LLM and agentic orchestration layer
Choose an LLM based on your constraints. Add an agentic orchestration layer using frameworks like LangChain Agents, CrewAI, or AutoGen.
In this step, you define whitelisted tools and their schemas, version them, and restrict allowed actions. Decide how agents select tools, how many reasoning steps are allowed, and how to handle retries or verification.
For example, when a sales leader asks: “Show me last quarter’s top 10 at-risk accounts and summarize why they’re slipping,” the agentic RAG flow might:
- Use RAG to pull recent QBR notes and support tickets
- Call a CRM tool to fetch pipeline and renewal data
- Run a simple risk scoring function
- Generate a ranked list with explanations
Pro tip
Every tool in the agent layer should have a version number, an input schema, an output schema, and a list of allowed actions. If an API changes downstream, the agent will fail gracefully due to a version mismatch instead of producing corrupt outputs or hallucinatory tool calls.
4. Integrate memory and multi-step reasoning
Agents become truly valuable once they can remember context and engage in multi-step reasoning, rather than simply answering a single question and stopping. This requires combining short-term and long-term memories, such as conversation history and validated facts.
Most production systems use components like LangChain’s memory modules, LlamaIndex’s index abstractions, or AutoGen’s multi-agent dialogue patterns to support these capabilities. With memory in place, you can design deliberate agent behaviors, such as:
- “Verify retrieved content before answering”
- “If context isn’t enough, re-query with a refined search”
- “Cross-check results from two solutions and reconcile them”
Now, instead of stopping at the first retrieval, the agentic RAG system checks, refines, iterates, and constructs a stronger answer.
Pro tip
Establish a strict “reasoning budget” per query to prevent runaway loops. Set hard limits, such as 5 tool calls, 3 refinement cycles, and 2 self-verification passes. Once the agent hits the budget, it must summarize progress and return control. This keeps multi-step RAG systems predictable, safe, and cost-efficient.
5. Ensure security and compliance for private data
To protect your agentic RAG system, secure data in transit and at rest. Apply Transport Layer Security (TLS) to all traffic and encrypt indexes, storage, and logs. Impose role-based access control (RBAC) so retrieval is restricted to the permission of the requesting user.
In addition, apply prompt-level governance to ensure sensitive fields are never echoed back in model responses, even if they appear in the underlying source, and map all controls to the standards your business follows, such as GDPR, HIPAA, SOC 2, or ISO 27001.
When regulations or internal policies demand stricter data residency, isolate your LLM layer in a VPC or on-prem environment to keep everything inside your controlled perimeter.
Compliance-first agentic RAG — security checklist
Add this checklist to improve scannability and AI extractability of the security section:
- TLS encryption on all data in transit
- Encryption at rest for vector indexes, storage, and logs
- Role-Based Access Control (RBAC) — retrieval scoped to individual user permissions
- Prompt-level governance — sensitive fields (PII, PHI, PCI) never echoed in model responses
- Compliance mapping — GDPR, HIPAA, SOC 2, ISO 27001
- VPC or on-prem LLM deployment for strict data residency requirements
- Audit trail logging for every agent action and tool invocation
- Automated PII/PHI detection and redaction before embedding generation
Pro tip
Instead of forcing your teams to adjust to a rigid architecture, we at Intuz work backward from your existing security questionnaires, compliance frameworks, and internal audit requirements, and design the entire agentic RAG stack to fit those rules from day one.For example, if you’re a healthcare provider operating under HIPAA, we deploy the LLM and vector store within your VPC, automatically redact PHI before embedding, and implement audit trails that satisfy your compliance officer’s requirements without exposing any patient data.
6. Test, validate, and deploy the agentic RAG system
First, define a comprehensive test suite that includes standard test cases, FAQs, analytical queries, and deliberate “trick prompts” designed to surface hallucinations, leakage risks, or incorrect tool usage. Next, measure the metrics that matter in production:
- Latency per request
- Human-rated answer quality
- Tool or agent failure rates
- Retrieval precision/recall on controlled queries
Next, run simulations by feeding the system anonymized historical queries from email, chat, tickets, or support logs to observe how it behaves under realistic load and ambiguity.
Once validated, deploy behind controlled interfaces, such as REST or GraphQL APIs, internal Slack or Teams chatbots, or embedded panels in CRM, BI, or intranet tools.
Finally, establish monitoring and feedback loops with tools like LangFuse or Phoenix to log prompts, traces, tool calls, errors, and human evaluations. Then feed these signals back into your retrieval configuration, prompts, and agent policies.
Pro tip
Build a regression suite using real (anonymized) historical queries that previously broke your internal search or workflows. These “pain point prompts” are far more effective than synthetic tests. Include examples like: Incomplete contextContradictory instructionsOutdated source referencesJargon-heavy domain questions If your agentic RAG system can handle these, it will handle 95% of real traffic.
Why Partner with Intuz for Implementing an Agentic RAG System
Building an agentic RAG system on private enterprise data isn’t a plug-and-play project — and most implementations fail not at the LLM layer, but at data preparation, retrieval quality, and security governance. Intuz approaches every engagement with an engineering mindset anchored in those fundamentals.
Intuz understands your data shape, designs a clean retrieval pipeline, selects the right orchestration layer, and builds agents that behave predictably in your environment. We have experience with agent workflows, vector indexing strategies, and secure enterprise deployment.
We also handle the hard parts that most businesses prefer not to manage internally: controlled data ingestion, metadata governance, retrieval quality tuning, RBAC, secure hosting options, and monitoring loops that keep the system reliable as your content evolves.
Everything is built within your own cloud boundary, aligned with your security and compliance requirements. If you choose to explore this with us, the first conversation stays practical.
We walk through your data sources, your reporting workflows, the decisions you want to support, and the systems your teams rely on. You leave with a clear sense of what an agentic RAG system would look like for you.
Book a free consultation with Intuz today.
FAQs
How do I securely connect my private enterprise data to an agentic RAG system?
Use a hybrid setup: keep data inside your VPC, expose it through a controlled retrieval API, apply row-level permissions, and enforce audit logging. Use encrypted vector stores (like PGVector or Pinecone VPC mode). Agents should only access data via policy-guarded tool calls.
What’s the best architecture for agentic RAG in an enterprise environment?
A solid stack includes: ingestion pipeline → embedding service → enterprise vector DB → RAG orchestrator → policy-enforced agents. Use event-driven tools (Kafka/SQS) for updates, a central retrieval gateway to standardize queries, and an agent supervisor that validates each tool call before execution.
How do I keep answers updated when internal documents change frequently?
Use incremental ingestion: detect file deltas via webhooks or change logs (SharePoint, GDrive, Confluence). Re-embed only modified chunks, push them to the vector index, and trigger cache invalidation in your agentic planner. This avoids full reprocessing and keeps responses aligned with new policies or product updates.
How do I prevent hallucinations when agents take actions based on retrieved data?
Introduce retrieval-grounding checks: each agent action must reference a citation ID from the vector store. A supervisor agent validates citation–content alignment. If confidence drops, force a fallback to a verification tool (SQL lookup, document fetch, or API check) before finalizing the response or action.
What skills and team setup are needed to build Agentic RAG system internally?
You need three roles: data engineer for pipelines and VPC integrations, ML engineer for embedding/RAG tuning, and backend engineer for tool endpoints. Optional: governance lead to manage access and audit. Without these, partner with an AI development company familiar with enterprise-grade agent orchestration.
What is the difference between agentic RAG and fine-tuning an LLM?
Fine-tuning modifies the model’s internal parameters to specialise its behaviour — it is a permanent change that requires retraining when data changes. Agentic RAG leaves the model intact and retrieves updated information dynamically at query time. For enterprise environments where data changes frequently, agentic RAG is typically preferred: it is faster to update, more auditable, and eliminates retraining costs. Fine-tuning and agentic RAG can also be combined — a fine-tuned model can serve as the reasoning layer within an agentic RAG architecture.
How does agentic RAG reduce hallucinations compared to standard RAG?
Agentic RAG reduces hallucinations through three mechanisms: (1) retrieval grounding — every agent response must reference a citation ID from the vector store; (2) supervisor agent validation — a reviewer agent checks citation-content alignment before finalising the answer; (3) confidence thresholds — if confidence falls below a set level, the system triggers a fallback verification tool (SQL lookup, document fetch, or API check) rather than generating an unsupported answer. This iterative self-correction loop is the primary reason agentic RAG outperforms standard RAG on complex enterprise queries.


