Many businesses have valuable data stored on their own servers but can’t fully use it because of privacy or compliance limits. In this blog, you’ll learn how to build powerful AI agents that work securely with your on-premises data using RAG (Retrieval-Augmented Generation) and Private LLMs. Also, how Intuz, an experienced AI agent development company, helps businesses turn isolated data into intelligent, secure, and efficient AI-driven workflows.
Businesses that handle sensitive internal data often face compliance barriers that make public cloud AI tools impractical. Sure, the productivity gains are clear. But the reliance on external data environments introduces governance and confidentiality risks that may not be acceptable.
The good news is that a new generation of on-premise AI agents is emerging to close that gap.
Deployed entirely on your infrastructure and trained on your private data, they use Retrieval-Augmented Generation (RAG) and private LLMs to deliver precise, context-aware responses within a fully contained environment.
Research shows that 67% of enterprises pursuing “data sovereignty” have already shifted to some form of private AI infrastructure, primarily to strengthen regulatory compliance and data control. For smaller businesses, that priority is even more critical.
Limited resources mean every decision about data handling has to be intentional, secure, and, of course, cost-justified. This blog post does a deep dive into setting up and maintaining on-premise AI agents with RAG and private LLMs.
Show
- 67% of enterprises pursuing “data sovereignty” have already shifted to some form of private AI infrastructure — primarily to strengthen regulatory compliance and data control.
- On-prem AI agents run entirely on your own infrastructure using a five-layer architecture: private data sources, a vector database (FAISS, Qdrant, Milvus), a RAG pipeline, a private LLM (LLaMA 3, Mistral, Falcon), and an agent framework (LangChain, LlamaIndex, Haystack).
- The build follows four steps — prepare and embed your data, deploy your private LLM and connect the RAG pipeline, integrate the agent framework, then secure, containerize, and monitor.
- Open-source private LLMs can match or exceed GPT-3.5-level performance on most enterprise benchmarks at roughly one-tenth the cost per token, with LoRA/QLoRA fine-tuning keeping hardware costs manageable.
- Security is built in by design — RBAC, encryption at rest and in transit, private VPC endpoints, Docker/Kubernetes containerization, and canary deployments keep sensitive data fully contained on your premises.
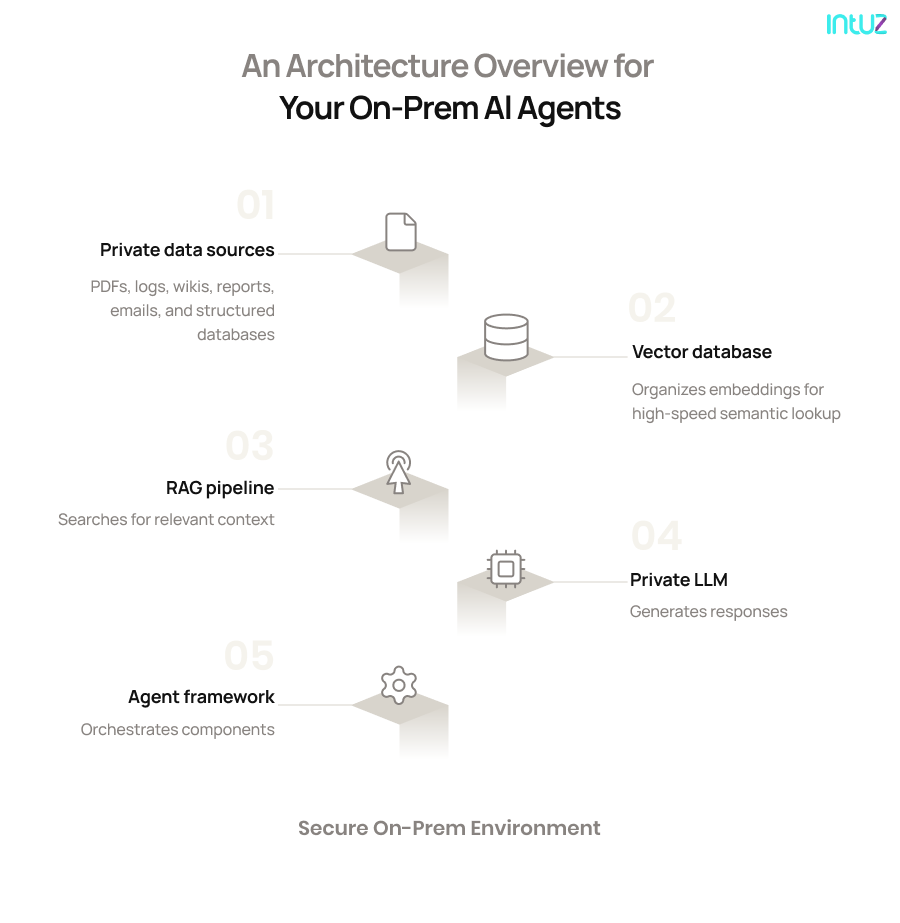
An Architecture Overview for Your On-Prem AI Agents
1. Your private data sources
These include everything your business already owns: PDFs, logs, wikis, reports, shared drives, email archives, help-desk tickets, and structured databases, forming the foundation from which your AI agents will learn.
2. Vector database
Once your data is processed, it’s converted into embeddings, which are numerical vectors that organize and capture high-speed semantic relationships. These embeddings are stored in a vector database, such as Facebook AI Similarity Search (FAISS), Qdrant, or Milvus.
3. RAG pipeline
The RAG pipeline connects your stored data with the language model. When a query comes in, it searches the vector database to find the most relevant context and attaches it to the prompt before sending it to the model. That’s how your responses stay contextually accurate.
4. Private LLM
This is your locally hosted language model, which could be LLaMA 3, Mistral, or Falcon, deployed according to your infrastructure setup. It generates human-like responses based on the information supplied by the agentic RAG system.
Because the private LLM runs on your servers or within a secure virtual private cloud (VPC), no external provider ever touches your data.
5. Agent framework
This layer serves as the brain that orchestrates how various components, such as the vector database, RAG pipeline, and language model, interact. Software frameworks such as LangChain, LlamaIndex, and Haystack help you define the logic, memory, and decision flows for your AI agents.
How to Build On-Premise AI Agents with RAG and Private LLM (Step-By-Step Guide)
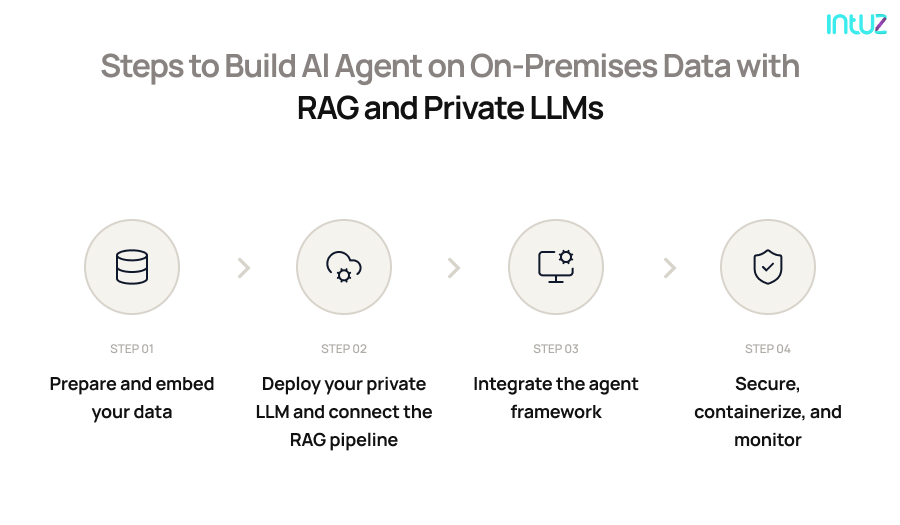
1. Prepare and embed your data
Everything your AI agents learn begins with your internal data. Therefore, before you connect any models or pipelines, make sure existing documents and systems are clean, readable, and consistent.
Remove duplicates, fix broken formatting, and convert legacy files into a standard format, such as plain text or JSON. If you work with images or scanned PDFs, use OCR to extract the text. The goal here is to make every piece of information machine-readable.
After your content is ready, generate embeddings to capture relationships between words and phrases so your AI agents can later efficiently fetch relevant information. You can use a locally hosted model, such as Instructor XL or Text Embedding 3 Large, for this.
Once generated, store the embeddings in an on-premises vector database, such as PGVector, along with metadata, including timestamps, titles, and document sources. When you properly perform this step, your AI agents are in a better position to answer questions like:
“When was the last system update?”
Or
“Which tasks are scheduled for next quarter?”
That, too, without sending any information outside your premises.
Pro tip
Automate embedding updates instead of regenerating everything manually. Use file-change detection tools, like Python’s watchdog or Linux Inotify (inode notify), to trigger updates only when new or modified files appear. This approach keeps your vector database aligned with live business data while minimizing compute load.
Did You Know?
88% of businesses struggle to achieve mature AI capabilities primarily because their internal data is incomplete, inconsistent, or poorly cataloged. — Accenture
2. Deploy your private LLM and connect the RAG pipeline
With your data embedded and stored locally, host your LLM in a secure environment, either fully on-premise or inside a private VPC. Open-source models like LLaMA 3, Falcon, or Mistral can run effectively on optimized hardware with strong GPUs or high-memory CPUs.
In fact, they can match or exceed GPT-3.5-level performance on most enterprise benchmarks—at one-tenth the cost per token.
If you want your AI agent to speak your business language, fine-tune or adapter-train your model using LoRA or QLoRA techniques. These methods adjust the model for your domain without retraining from scratch, keeping hardware costs manageable.
Once the model is ready, integrate it with your RAG pipeline through a retrieval interface that handles both query parsing and context injection.
When a user arrives, a retriever module converts their input into an embedding vector and performs a similarity search against the database.
Top-ranked results are then passed through a context filter that removes redundancy, enforces token limits, and orders passages by semantic relevance or recency.
The final prompt package, composed of the user query, system instructions, and curated context, is then forwarded to your private LLM via a local API or inference server. This process ensures the agents don’t “hallucinate” or guess; instead, they rely on verified information sources.
Pro tip
Benchmark your private LLMs using domain-specific evaluation sets, not generic benchmarks. You could routinely build “golden datasets” of 50–100 internal queries (like compliance FAQs, operational procedures, or sales objections) to measure accuracy drift and latency.
3. Integrate the agent framework
With your data pipeline and private LLM in place, the next step is to give your system structure – a way for it to think, decide, and act. An agent framework orchestrates how your AI retrieves data, calls tools, and delivers responses that feel purposeful instead of reactive.
Therefore, pick LangChain, LlamaIndex, or Haystack —and within it, define the tools your agents will use. That could include a database lookup function, a document summarizer, or a vector search interface.
You can also implement task or conversation memory, allowing your agents to recall earlier interactions in a session or reuse relevant context for related queries.
Pro tip
Treat your agent framework like an evolving system. Pick one or two critical workflows, such as summarizing daily sales trends or generating support ticket insights. Then, expand into multi-agent systems or cross-department scenarios.
Did You Know?
AI agents help employees save an average of 28 minutes per day, up to two hours for some, enabling them to focus on higher-value tasks that might otherwise get sidelined. — Microsoft
4. Secure, containerize, and monitor
When your AI agents can read and act on your private data, security and reliability become central design goals. Therefore, implement role-based access control (RBAC) so that only authorized services and users can query the multi-model AI systems or pull documents.
Encrypt data at rest and in transit and rotate keys regularly. Keep model endpoints behind internal networks or a private VPC. Ensure you have the capability for service-to-service authentication for any tool your agent calls.
Next, containerize your components with Docker and orchestrate them with Kubernetes or another scheduler you trust. This makes it easier to replicate environments, deploy updates, and isolate workflows.
In addition, use namespaces and network policies to limit lateral movement inside your cluster. For that, collect logs for queries, retrievals, and generation outputs, and track throughput and retrieval accuracy.
Set alerts for unusual patterns, such as spikes in failed queries, unusually long response times, or repeated access attempts from an unexpected source.
Pro tip
Controlled rollouts detect production-impacting issues up to several weeks earlier and with 3X–10X higher sensitivity than traditional phased rollouts. Therefore, before any release, validate every model, retriever, and connector inside a staging environment seeded with synthetic or redacted data to confirm that security boundaries and data flows behave as expected. Use canary deployments to roll out new model versions or RAG logic incrementally, routing a small percentage of traffic to the updated service until you’re ready to migrate fully.
How Intuz Builds a Powerful Bidirectional Speech App – Case Study
We partnered with a forward-thinking client to develop a two-way Text-to-Voice and Voice-to-Text mobile application, showcasing our expertise in AI-driven voice technology. The solution delivers the following capabilities wrapped in an intuitive interface:
- Dynamic bidirectional conversion
- Real‑time transcription
- Multilingual support
Every feature is backed by secure integrations and seamless sharing across platforms, making communication more accessible than ever.
How Intuz Helps Build On-Prem AI Agents With RAG and Private LLM for Your Business
We’ve outlined all the steps in this blog and included relevant advice to help you prepare. However, to make that transition smooth and sustainable, you need a partner that’s comfortable working deep inside your stack, not just advising from the outside.
That’s where Intuz comes in.
We’ve helped businesses across industries design on-prem AI architectures that balance control, compliance, and speed.
Our teams work inside your cloud environment, follow your IAM policies, and hand over fully documented systems that you can continue to manage independently.
You also gain from our outcome-first approach. Every engagement starts with a concrete goal: deploying a model, passing an audit, or cutting cloud costs. Pricing is transparent and aligned to that outcome.
Plus, security is baked into every stage. Our facilities are ISO 27001-audited, and our delivery practices meet GDPR, SOC 2, and HIPAA requirements.
We sign GDPR-compliant DPAs, run encrypted devices with MFA, and carry enterprise-grade cyber insurance for complete peace of mind.
We also rely on proven frameworks such as Kubeflow, Flyte, and MLflow, ensuring your systems remain vendor-independent, auditable, and easy for future engineers to maintain.
If you’re ready to explore what an AI agent built on your own data could look like, let’s hop on a short discovery call to discuss our custom AI development solutions.
Let’s Book a free consultation with Intuz today!
We’ll map one of your workflows and show you how a secure, private AI system can run on your infrastructure, not someone else’s.
FAQs
What are the hardware requirements for running an on-prem AI agent with RAG and a private LLM?
You’ll need substantial CPU or GPU resources, ample RAM, high-speed SSD storage, and a secure network environment. For most enterprise-grade agents, at least one modern GPU (e.g., NVIDIA A100) and 64 GB RAM are recommended. Requirements may scale up for heavy retrieval workloads or larger models.
How do I set up document ingestion and indexing for RAG on-prem?
Start by collecting all relevant enterprise documents, then preprocess data—chunk, clean, and embed using vector databases like Milvus, Qdrant, or FAISS. Automate regular indexing to keep the retrieval accurate and fresh as business data evolves.
How can I ensure security and privacy of my data when building on-prem RAG agents?
Deploy all components inside a secure, private network with strong authentication and access controls. Ensure all data stays on-prem with no outbound API calls. Use encrypted storage and consider running agents in containerized environments for robust isolation and compliance.
What open-source LLMs and frameworks are recommended for on-prem RAG agents?
Popular options include Llama 4, DeepSeek R1, Mistral 3.1, and open-source packages like Ollama for LLM deployment. Frameworks such as LangChain or Haystack offer flexible APIs for integrating LLMs, RAG, and workflow automation seamlessly in local environments.
How do I optimize RAG agent performance and accuracy with private data?
Focus on domain-specific fine-tuning of your chosen LLM and test chunking, indexing, and reranking strategies on your actual data. Iteratively adjust retrieval pipelines, model parameters, and filter noisy data, using business-oriented evaluation metrics to ensure practical relevance for end users.