

Choosing between MCP and RAG can significantly impact how efficiently your business builds and scales AI systems. This blog breaks down both architectures with practical comparisons, real-world use cases, and decision frameworks to help you pick the right approach based on your data needs, automation goals, and long-term AI strategy.
Most SMEs operate on systems like CRMs, ERPs, ticketing platforms, spreadsheets, and shared documents. When it comes to adding AI into the mix, the priority is to assess how it will integrate with these existing workflows and deliver value without disrupting daily operations.
Two patterns show up quickly in that conversation:
- Retrieval-Augmented Generation (RAG)
- Model Context Protocol (MCP)
They sound similar because both give models “access” to something. However, the two terms address different problems and lead to significantly different architectural and cost decisions.
This blog guides you through how MCP and RAG work, the changes to your stack that occur when you adopt either of them, and how to determine which approach best fits a given workflow.
Show
- RAG grounds AI responses in your existing documents and knowledge stores, while MCP enables AI to actively connect with live tools, APIs, and systems — they solve fundamentally different problems.
- A typical RAG workflow covers five stages: ingestion, query embedding, retrieval, context construction, and generation — making it best suited for document-heavy and knowledge-retrieval tasks.
- MCP operates through tool registration and structured execution, allowing AI agents to query CRMs, ERPs, billing systems, and internal APIs in a controlled and auditable way.
- RAG is generally lower in upfront cost and more predictable in performance, while MCP has a higher setup cost but delivers greater operational automation over time.
- Many real-world workflows benefit from combining both: RAG clarifies what should happen by interpreting documentation, and MCP carries out the required action inside live systems.
What Is RAG?
RAG is an AI technique that combines information retrieval with Large Language Models (LLMs) to generate more accurate and context-aware responses.
It utilizes an external source, such as a database or document repository, to fetch relevant information and ground the model’s answer.
What Is MCP?
MCP is an open standard developed by Anthropic that enables AI agents to dynamically connect with and leverage external tools, APIs, and services in a structured manner.
It acts as a universal “connector” or “language” for LLMs, enabling them to go beyond their static, pre-trained knowledge to:
- Access real-time information
- Perform specific actions
- Become more automated
How Each Architecture Works: RAG and MCP
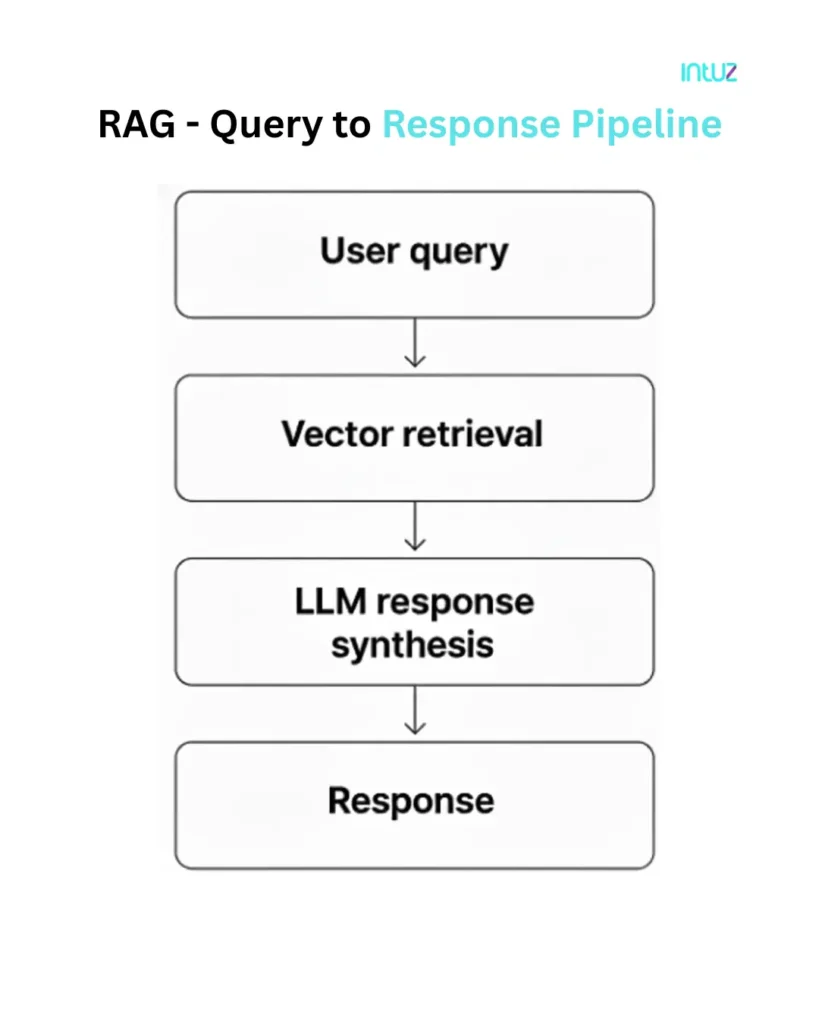
How an RAG architecture works
RAG is a five-part workflow, comprising:
- Ingestion: Your documents, tickets, emails, and records are cleaned, chunked, and indexed in a vector database, with metadata, such as source, author, date, and permissions
- Query embedding: A user asks a question, after which the system converts it into an embedding, using the same embedding model used during ingestion
- Retrieval: The vector database returns the top chunks closest to the query embedding; filters can be applied, for example, by user, department, or document type
- Context construction: The system builds a prompt containing the user question, the retrieved chunks, and possibly some system instructions
- Generation: The language model reads the prompt and produces an answer, often with citations linking to the underlying documents
Insight
86% of organizations using GenAI prefer augmenting their LLMs via frameworks like RAG, rather than relying solely on out-of-the-box models. — K2view
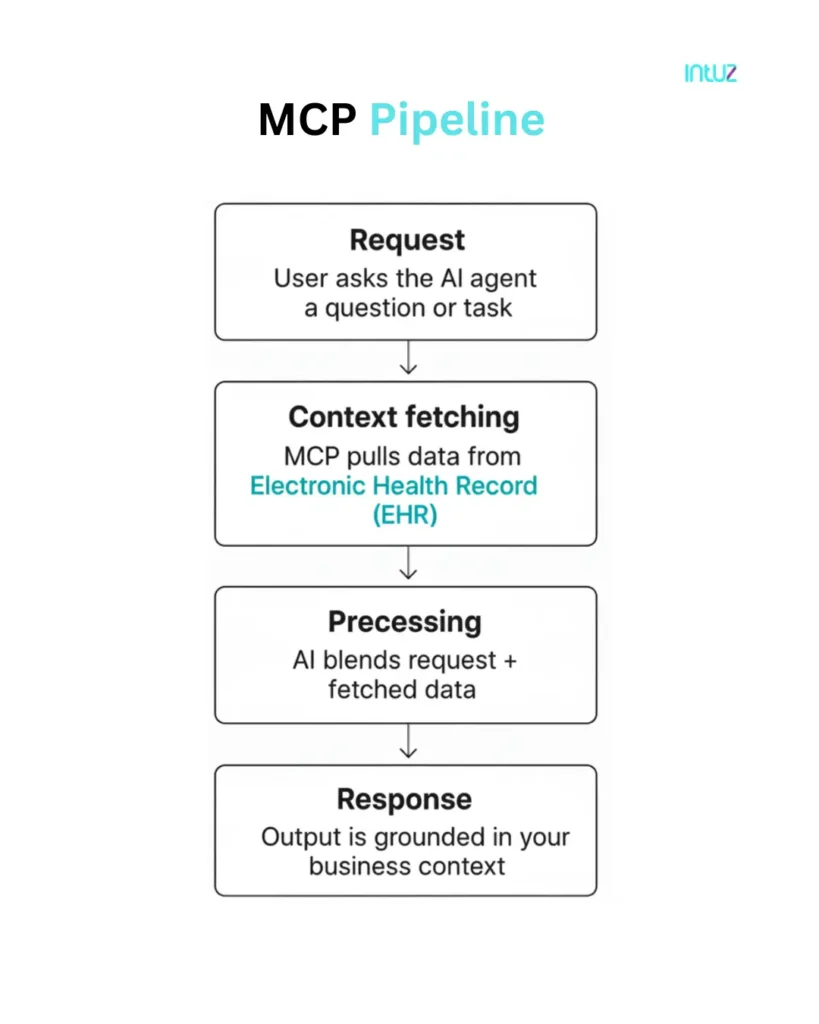
How an MCP architecture works
A typical MCP-based setup comprises five steps:
- Tool registration: Each external system (CRM, billing, ticketing, analytics, and internal APIs) is wrapped as a tool with defined inputs, outputs, and allowed operations
- Instruction analysis: The model receives an instruction; MCP exposes available tools, and the LLM decides which tool matches the request
- Tool execution: MCP sends structured requests to the selected tool(s), which might run a database inquiry, an API call, or a workflow action
- Result handling: The tool returns the structured data or status responses; MCP feeds that back to the model as context
- Response or next action: The model decides whether to call another tool, return a result to the user, or do both
Insight
By 2027, 70% of new digital business applications will rely on APIs to connect data and services. — Gartner
Key Differences Between RAG and MCP
| Parameter | RAG | MCP |
|---|---|---|
| Data Flow | Pulls from a pre-built, indexed knowledge store | Calls live systems that compute or fetch data on demand |
| Latency Pattern | Mostly bounded by vector search and one model call | Includes tool latency, network hops, and model calls |
| Failure Modes | Poor retrieval quality, outdated content, embedding drift | API errors, schema changes, rate limits, tool timeouts |
| Determinism | More stable, as content changes less frequently | More variable, as external systems and data change often |
| Security Focus | Document ACLs, PII handling, storage encryption | API scopes, action permissions, audit of side effects |
| Observability | Monitoring retrieval quality and content freshness | Tracing tool calls, tracking actions, and debugging sequences |
Use Cases Explained: Which Workflows Fit RAG vs. MCP
When to use RAG
Opt for RAG when your primary problem is, “We have the answers. But nobody can find them quickly or use them consistently.” For example:
1. Technical or product documentation
Your product changes often, and customer support, sales, and tech teams rely on scattered folders, email threads, and old tickets. RAG helps each team ask questions in natural language and pull up the most relevant parts of the resources.
2. Policy, legal, and compliance material
Contracts, HR policies, security guidelines, and SOPs create a heavy information load. RAG provides fast, reliable summaries and references in real-time, so teams can quickly access the relevant clause or rule without needing to scan lengthy PDFs.
3. Internal knowledge search
You don’t want your team to spend hours sifting through shared drives, chats, wikis, and outdated tickets. RAG provides a single interface where users can type a question and receive an answer grounded in your existing content
When to use MCP
Reach for MCP when your main problem is, “We have tools that demand manual clicks and updates, and we want AI to work inside those tools safely.”
1. Back office workflows
Finance and ops teams fetch data from multiple systems, reconcile it, and update trackers. MCP can query the systems directly and return a consolidated view that the model can use immediately.
2. Sales and CRM operations
Reps update deals, log activities, and define follow-ups. An MCP-driven assistant can read the simple instruction, apply it to the correct CRM records, and perform those updates in a controlled, auditable environment.
3. Reporting and analytics preparation
If someone asks for “this week’s pipeline by region” or “open invoices for XYZ customer,” MCP can prompt your BI tool or data API, feed the results to the model, and return a clean explanation.
When businesses can combine RAG and MCP?
Yes! Many real scenarios need both knowledge and action—for example:
- A workflow starts with understanding a document, then requires an update in a system
- You want an assistant who can explain a situation, then take the next step
- A decision needs both policy context and live numbers from your tools
In such cases, RAG and MCP don’t compete with each other. Instead, they form layers in one system, which in practice look like:
- RAG clarifies what should happen by interpreting your documentation or prior examples
- MCP carries out what should happen by querying systems or executing the next step
Let’s take a simple legal or compliance scenario
A retail store manager asks the AI assistant whether a product’s price should be adjusted after the supplier increases costs.RAG provides the reasoning foundation. The assistant retrieves the pricing policy, margin rules, and past similar cases to explain how such changes are usually handled.MCP then executes the operational checks and actions. The assistant gets the product’s live cost and current price, checks inventory and any active promotions, and creates a pricing update request if the store manager approves.
Intuz Pro tip
If you plan to use RAG and MCP together, separate the two layers in your architecture. Keep retrieval, embeddings, and ranking pipelines independent from the MCP tool layer.This gives you cleaner observability (you can see whether failures come from retrieval or from a tool), the ability to scale vector search and tool execution separately, and safer fallbacks when tools fail or return incomplete data.
Also Read
Performance, Cost, and Maintenance Comparison: RAG vs. MCP
| Category | RAG | MCP |
|---|---|---|
| Speed | Responds quickly once content is indexed. Speed depends on vector search and a single model call. For document-based questions, performance stays consistent. | Depends on external tools. If a CRM or billing API is slow, the assistant waits. When tools respond quickly, MCP feels fast. When they slow down, latency grows. |
| Scalability | Scales with how much data you store and how often it changes. Adding new documents means scheduling ingestion jobs and keeping the index fresh. | Scales with the number of systems you integrate. More tools expand capabilities but increase the work of keeping each integration healthy. |
| Cost | Lower upfront cost. Set up ingestion, indexing, and retrieval. Ongoing costs remain stable unless data grows quickly or needs frequent reprocessing. | Higher setup cost. Each tool must be connected, tested, and monitored. Over time, it reduces manual updates and repetitive tasks. |
So, How Do You Decide Between RAG and MCP?
Use this checklist to evaluate whether a use case should use RAG, MCP, or both.
Choose RAG if:
- The work relies on documents, policies, guides, or stored knowledge
- You need consistent answers grounded in your own material
- Questions often start with What, Explain, Where, or Summarize
- Accuracy depends on reading the right source text, not real-time data
Choose MCP if:
- The task updates records or performs steps inside a tool
- You depend on systems like CRM, ERP, billing, ticketing, or analytics
- You need structured actions, not just explanations
Choose a Hybrid Approach if:
- A task starts with reading a document and ends with updating a system
- You need both past guidance and real-time numbers
- You want one assistant that can explain and act
Meet Intuz: Your Partner for RAG, MCP, and Enterprise AI Solutions
When exploring either of the techniques for your SME workflows, you want to avoid guesswork and move forward with confidence. We at Intuz bring practical experience from real production environments.
To begin, much of our work involves establishing robust RAG foundations, particularly for teams that rely heavily on extensive written materials.
A recent example is our project for a pharmaceutical client, where we built a RAG-powered research system that reads thousands of scientific papers and clinical studies.
The system turns dense data into clear, dependable insights and supports complex scientific questions without overwhelming researchers with raw text.

The approach applies well beyond pharma. Any business that handles large document sets, from compliance to support operations, benefits from the same discipline in data ingestion, indexing, and retrieval accuracy.
We also support teams that rely heavily on software tools by building MCP server into their operational stack. From CRM systems and ERP platforms to ticketing tools and custom internal APIs, each one becomes part of a predictable flow that the AI can follow.
We manage the API wrappers, tool registries, and governance rules that ensure these interactions are safe and controlled. Instead of handing over a fragile prototype, we create a system your team trusts in a production setting.
What’s more, everything we build stays within your environment. Your cloud, your IAM rules, your repository structure. You maintain ownership of the models and data, which aligns with your internal security requirements and avoids lock-in.
If you’re keen to find out more, book a free consultation with our experts.
We’ll discuss your workflows, map RAG and MCP to the key components, outline a simple architecture, and provide a phased path that respects your constraints. Talk soon!
FAQs
What’s the core difference between RAG and MCP for real business use cases
Think of RAG as “give better answers using my company’s documents.” It pulls the right info and keeps responses factual. MCP is different—it lets an AI actually do things: call APIs, fetch data, update systems, or run multi-step workflows. If you only need accurate answers, use RAG. If you need automation, MCP wins.
RAG vs MCP – Which one is more cost-effective?
RAG is usually cheaper because you’re mostly paying for document search and LLM usage. It works perfectly for support, knowledge retrieval, or research-type tasks. MCP becomes cost-efficient when you’d otherwise build several microservices or integrations—it centralizes all actions into one AI layer. Most SMBs start with RAG and switch to MCP as workflows get more complex.
When does RAG fail, and MCP becomes necessary?
RAG breaks down in scenarios requiring real-time actions, structured decision flows, or multi-step dependencies—like checking inventory, calling APIs, or executing transactions. MCP shines when the AI must do something, not just answer. If your workflow requires context → reasoning → tool execution → verification, MCP is the more reliable architecture.
What data and engineering effort is required for each RAG & MCP?
RAG needs well-structured documents, clean chunking, good embeddings, and a solid vector database. It’s predictable and fairly straightforward. MCP needs more upfront engineering because each tool or API must be defined precisely. But once set up, it can automate huge parts of your operations. Content-heavy businesses lean toward RAG; operations-heavy teams benefit more from MCP.
Can RAG and MCP work together?
Absolutely—many US companies already run them side by side. RAG brings the facts; MCP uses those facts to take action. For example, RAG can fetch a policy document, and MCP can use that info to update a customer ticket or push data into your ERP. This combo is the most scalable path if you want accurate answers and reliable automation.


