The Comprehensive Guide to Serverless Architecture in 2026
Updated 6 Apr 2026

In this day and age, "serverless" seems to be the latest buzzword garnering much attention from the rookies and pros in the world of tech. The concept of "serverless" lives up to the hype. It promises the real possibility of ideal business implementations that sound pleasant to the ears and do not burn a hole in the pocket.
A serverless computing model enables developers to focus on the application, not the infrastructure. This is a relief as a significant amount of time is spent by developers on implementing, monitoring, maintaining, and debugging the infrastructure.
But what they want to do is code, make brilliant apps, and serve their customers—make them happy. With the advent of serverless computing services, time can be better channeled in the right direction to focus on the business goals applications fulfill.
Expectations aside, open-source serverless frameworks are used by many famous brands, including AOL, Reuters, Telenor, and Netflix.
Journey to the beginning of time
While the Amazon web services serverless architecture is the first of its kind in the market, many other IaaS public cloud platforms have followed suit. Lambda, for instance, requires no prior planning regarding resource usage or infrastructure management.
Similarly, Azure serverless computing was launched in November 2016 by Microsoft, enabling users to build, test, deploy, and manage apps through Microsoft-managed data centers. In addition, there is a growing number of startups offering the serverless computing platform.
Despite the progress made in the serverless stack, the market is still at a nascent stage. For both developers and businesses offering serverless, there is much to learn about the concept. Without further ado, let us dig deep into serverless architecture:
What is a serverless architecture?
Simply put, it refers to a cloud computing model where a third-party service hosts all applications, thus eliminating the need for server software and hardware management by the developers.
In such a scenario, they only have to write the application code and not have to spend time and energy on server management. Moreover, the application scales automatically, and the code only executes when invoked—thus making the apps faster and more efficient.
Some popular third-party cloud platforms are Google Cloud Functions, Iron.io, Webtask, Azure Functions, AWS Lambda, and IBM OpenWhisk.
According to Microsoft's CEO, Satya Nadella, serverless computation will change backend computing economics and disrupt the core of distributed computing.
Pros and cons of serverless computing solution
This is not only for private applications anymore. Many enterprise digital solutions are becoming cloud-based. Let us look at what makes serverless architectures stand out and where it still loses points in the market.
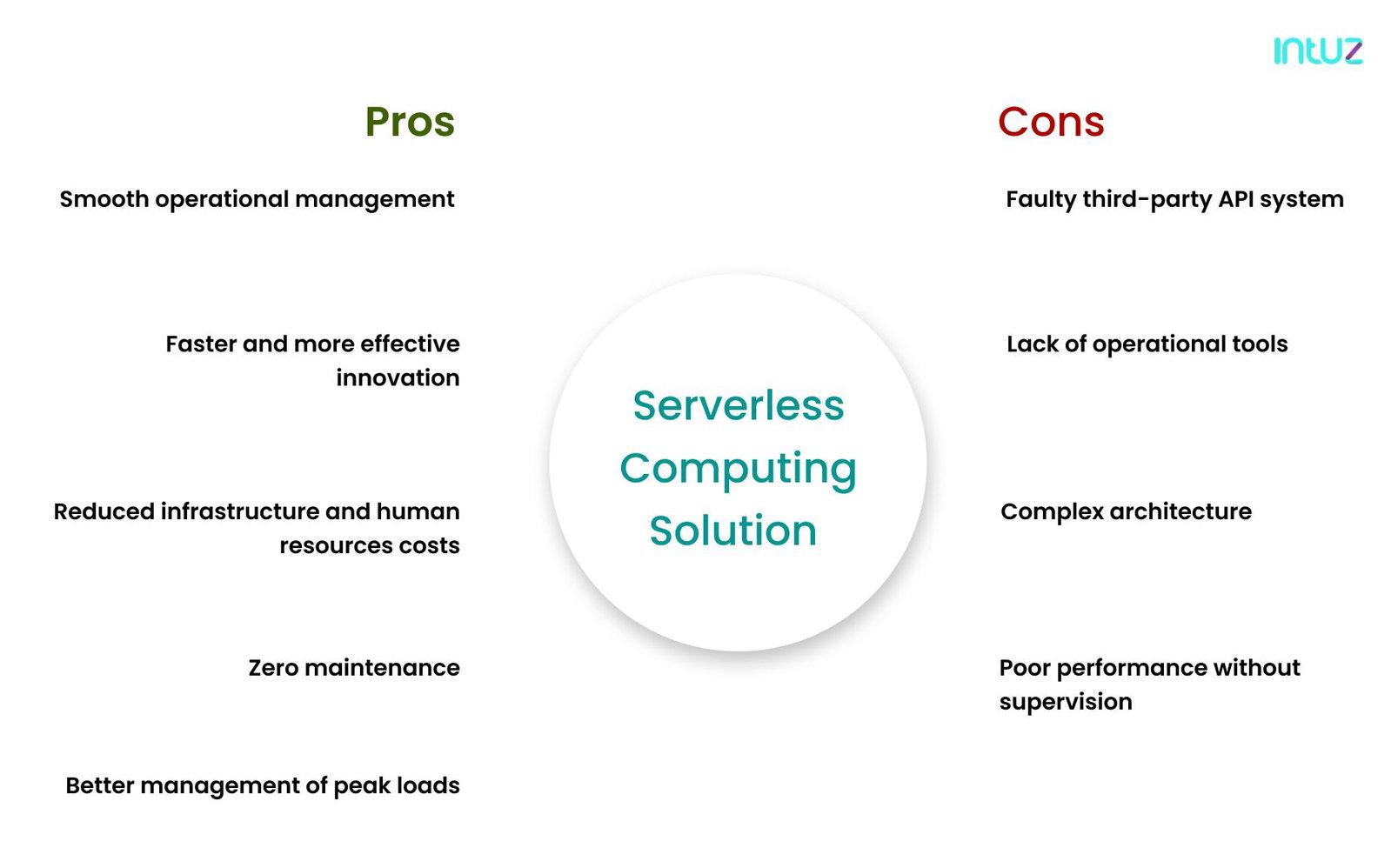
Pros
1. Smooth operational management
The serverless computing model separates infrastructure management services and applications running on the cloud platform. Because the serverless architecture allows the applications to scale up automatically, the operational management overheads are reduced.
That means developers have the mental bandwidth to manage and run the underlying platform and enhance the delivery of core services such as load balancers and databases. Since the developers do not need to write the code directly in the vendor console, the fully serverless computing tactic requires low to minimum supervision.
2. Faster and more effective innovation
This is obvious—as the serverless architecture eliminates system engineering problems in the application, developers can innovate rapidly. Meaning, they have the flexibility to experiment with new tactics, apply various agile methodologies, and update the serverless stack. Moreover, the issue of database storage and caching is also not handled by developers.
3. Reduced infrastructure and human resources costs
In the serverless computing solution, businesses pay for only managed servers, application logic, and databases. For instance, the Lambda serverless architectures bills only for the time when the serverless function was invoked. Due to this arrangement, the cost of running the Lambda framework is 95% less than running a server for the whole month.
4. Zero maintenance
The serverless computing model enables the developers to focus more on coding and less on the operations' nitty-gritty. That means no more wasting time purchasing, operating, and upgrading infrastructure because all of that does not form the business core.
5. Better management of peak loads
Developers have the authority to ensure the rapid provision of resources in real-time in a serverless architecture. That way, they can easily account for unforeseen peak leads and deal with disproportionate growth efficiently. Plus, one cannot deny the higher error tolerance possible because of the flexible hardware infrastructure present in the cloud platforms.
Instead, serverless computing services enable businesses to horizontally and vertically scale to meet the growing demand on the application, handle any resource provisioning necessary and ensure the application has a robust backend infrastructure it needs to run efficiently.
Serverless architectures for the client application comprises a web server, themselves from the engineering cycles—focus on what they are experts in doing—building a stellar application and services customers to the fullest.
Cons
While serverless computing services can be convenient and cost-effective, it is essential to understand that "serverless" comes with its own set of drawbacks. These may not seem so severe, but it is best to keep an eye out if you are new to the technology. Here you go:
1. Faulty third-party API system
Giving up the systems control while deploying APIs often leads to downtime, loss of functionality, massive overhead expenses, unexpected data limits, and so on. Multi-latency is also another fault seen in open-source architecture frameworks.
In fact, many PaaS companies have imposed governor limits due to multi-latent cloud platforms, prompting developers to be more careful lest they want to make grave mistakes or deal with high latency.
Having more APIs in the serverless computing services means being more prone to malicious attacks. That is because each API increases security implementations, making it difficult for developers to adhere to every time.
It is safe to conclude that multi-latent and open-source serverless frameworks come with security, performance, and robustness problems.
2. Lack of operational tools
In a serverless architecture model, debugging and monitoring activities are handled by vendors and not developers. This happens because user requests are handled by application load balancers such as Zuul, AWS API Gateway, and Geo DNS.
Therefore, whenever there is an outage in data storing services and caching, it is hard for developers to prevent the traffic from flowing to other regions. That is why switching vendors in a serverless computing platform is tricky.
However, as of today, there is only one feature, i.e., distributed tracing, that helps understand how a request flows across multiple cloud services and enables debugging systems based on the microservices architecture.
3. Complex architecture
Distributed modern architectures are complicated and time-consuming to develop. This includes both serverless architecture and microservices frameworks. Decisions about how small each function should require time to implement and test.
That is why it is necessary to balance the number of serverless functions one can have in modern architecture. Otherwise, it just gets too cumbersome and would lead to the creation of mini-monoliths on the cloud platform, which would ultimately impact the efficiency levels.
4. Poor performance without supervision
Since there are no servers to manage, many developers often overlook the performance aspect of the serverless stack. It is important to note that companies using serverless technologies are not free from the physics of fiber cuts, latency, or performance issues with the provider.
At the end of the day, they still need to make sure their users are not experiencing performance issues. Unlike traditional servers, the serverless computing model must not be continuously monitored from the backend to end-users' optimal performance. That takes a load off the developers, and they can focus on high-end development jobs.
Netflix - a classic example of serverless architecture

Netflix is considered a pioneer in leveraging serverless and uses AWS Lambda to provide 7 billion hours worth of video to 182 million customers worldwide. It is undoubtedly the ultimate choice for online streaming, and hence makes for one of the best serverless architecture examples to study. Here is how it has used serverless for its use:
a. Encoding
Since thousands of files are uploaded on Netflix daily, AWS Lambda helps in encoding, including tracking, aggregating, validating and tagging the videos so that the user gets an optimal viewing experience.
b. Backup
Lambda validates the data from the backend and copies it to the desired storage. Apart from that, it keeps a backup of everything—video content, software updates, and client information.
c. Safekeeping and monitoring
Data safety is paramount. Since it uses Lambda, the serverless providers highlight events - in the form of flags - if there are any issues and helps developers to resolve them asap.
How serverless architecture works
Hosting a software application on the interweb requires some server infrastructure. For instance, using a virtual server such as Microsoft or Amazon eliminates the need for physical hardware whatsoever.
However, it still requires developers to manage the operating system and web server processes. Serverless hides the operational complexity, but no server cannot be left without any supervision or management from a developers' point of view. Adding to that, here is how the serverless functions are written and executed:
- The developer writes a function whose main aim is to serve a specific purpose within the application code.
- The developer defines an event that triggers the cloud platforms to execute the function. For example, in this, it could be sending an HTTP request.
- The user then triggers the event [or sends for an HTTP] with a click or a similar action.
- The cloud platform checks if that function is already running. If not, it will start a new one.
- The result is then sent back to the user who sees the impact of the executed function inside the software application.
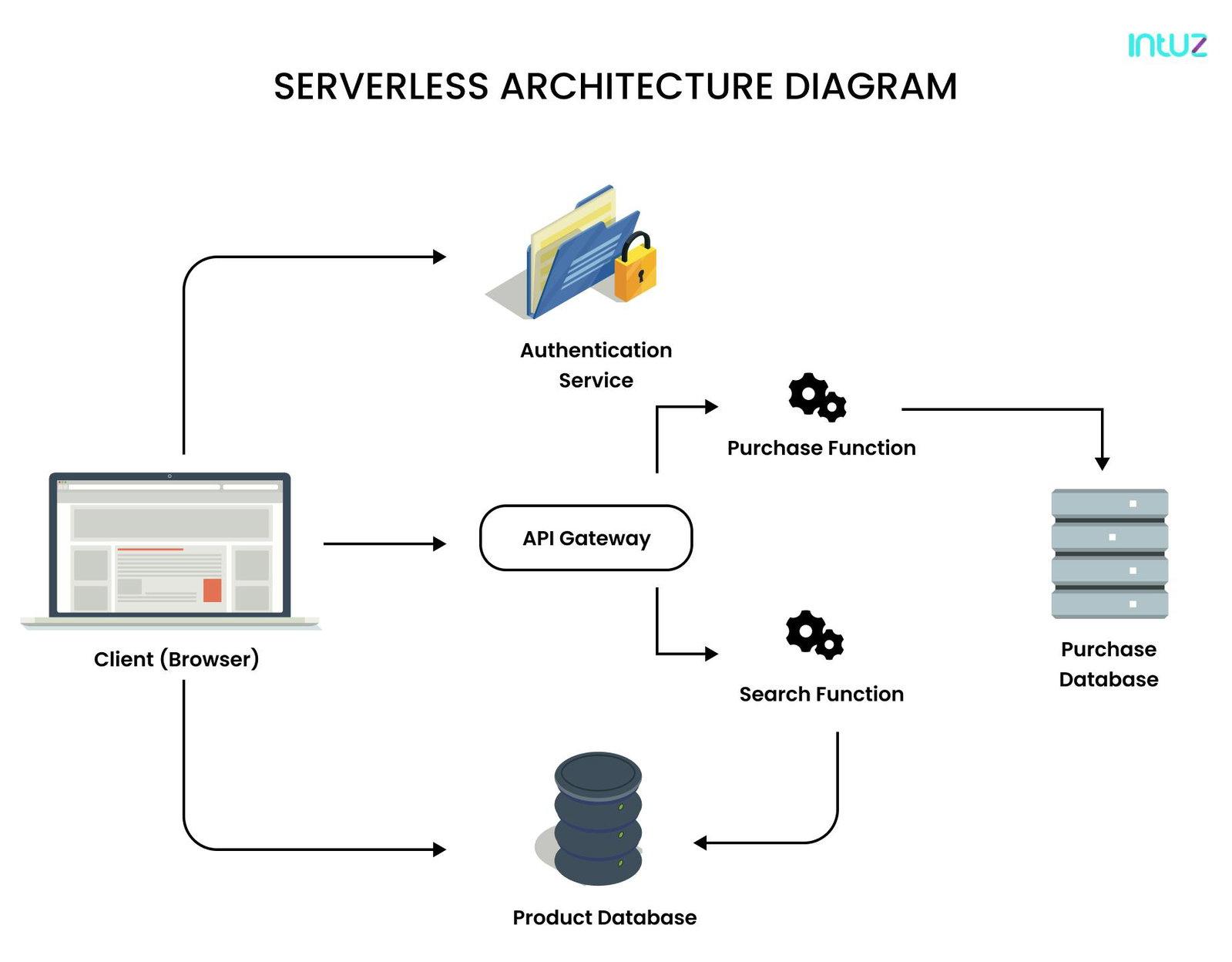
Serverless architecture diagram: how it works
Use cases of serverless architecture services
It is important to note that "serverless" is not right for every company. Therefore, it is best for those interested in serverless computing solutions to start with smaller applications that can be deployed quickly.
Serverless is ideal for running stateless applications, i.e., applications that do not maintain user state and data for a more extended period. It is cost-effective for those applications that do not require all components to run all the time. Serverless only charges when the code is executed.
Here are four use cases of serverless architectures solutions
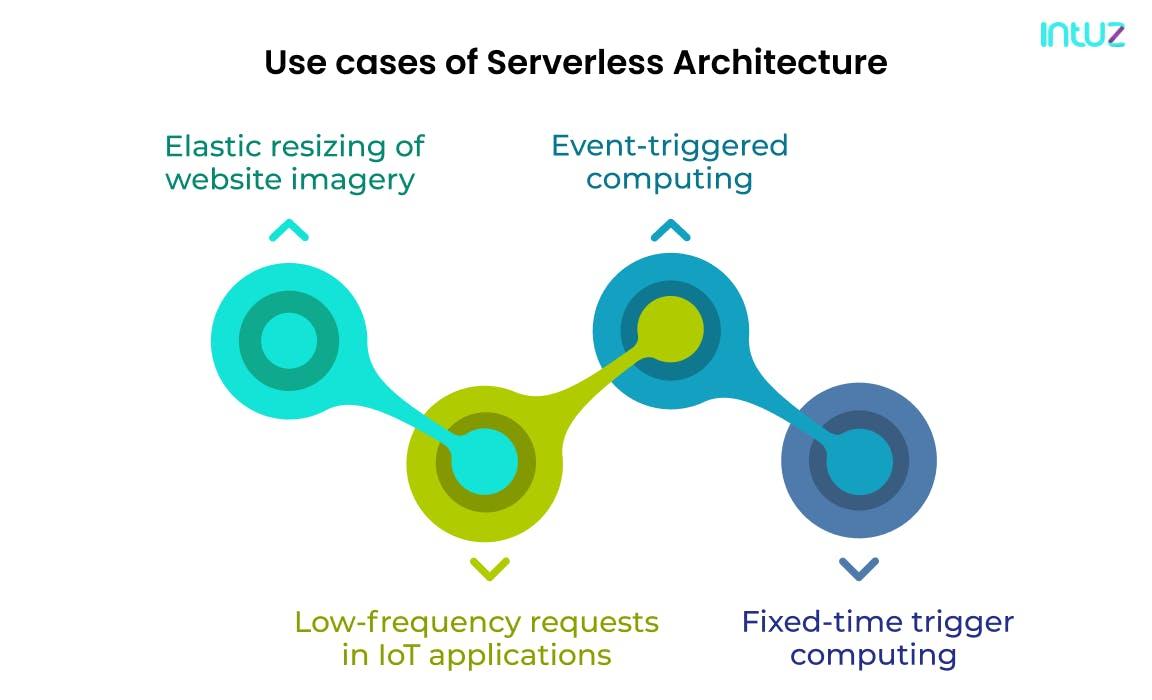
1. Elastic resizing of website imagery
When online product sellers build a repository of images, they have to dynamically resize the images in various formats or add different image watermarks. Those products have to be displayed on the web application.
When the images are uploaded to the Operations Support System [OSS], Function Compute is used to create custom function computing triggers. Based on different computing rules, images of various sizes are generated to meet different product display needs.
This process requires developers to manually intervene to ensure the aesthetics of a web page and also construct additional servers.
2. Low-frequency requests in IoT applications
There is no surprise that IoT devices transmit small amounts of data at regular intervals. That is what gives birth to scenarios that involve low-frequency requests.
For example, an IoT application may only run for 50 milliseconds in one minute, which means the CPU utilization is just under 0.1% per hour. In other words, the IoT gateway pushes Function Compute for processing smart device statuses.
Function Compute uses an API to send mobile push messages sent to mobile terminals for status confirmation and management. That is how 1000 identical IoT applications can share the same serverless computing solutions.
This is not only cost-effective but also solves efficiency issues. No wonder IoT devices function as smoothly as bread-and-butter and offer such a superior user experience.
Top IoT development tools & platforms with comparison [2021]
3. Event-triggered computing
Serverless can be applied to scenarios involving multiple devices that access various files; for example, mobile phones uploading text files, videos, and images. The same logic can be applied for user registration, including sending an email to verify the user's scenario.
In such cases, Function Compute set OSS triggers to receive event notifications. On the other hand, developers can write codes to process and transmit files to OSS or create custom events to trigger subsequent registration processes.
No additional application configuration or servers are required to process subsequent requests. Thanks to serverless computing services, the entire process is simple and scalable and relieves the developers from many menial tasks.
4. Fixed-time trigger computing
With evolving serverless computing services and significant investments from cloud pioneers such as Google, Microsoft, and Amazon web services, it is quite clear that the world is beginning to see how serverless computing models impact the way software applications are delivered and built.
Keeping that in mind, let us talk about the events that can be triggered at fixed times. For example, developers can have a service process transactional data submitted during peak hours at night or when the service is idle.
The time-triggered Azure serverless computing model allows developers to schedule a time for executing a specific function, including deciding month, day of the week, hour, minute, and second using the CRON expressions.
Developers can even run batch data for data report generation and remove the need for additional processing resources.
Understanding the serverless application framework
Since serverless is defined by stateless compute containers and modeled for event-driven solutions, third-party apps manage the server-side logic and state.
Serverless architecture for the client application comprises a web server, Function-as-a-Service solution, user authentication functionality, database, and a Security Token Service [STS]. In this section, we will discuss them all in brief:
- A web server includes all of the static HTML, CSS, and JS files for the application. Since the application's UI is best-rendered in JavaScript, it allows for a simple and static web server.
- A FaaS layer is the critical enabler in a serverless architecture as it enables the application services for logging in and accessing data. These functions read and write from the database and provide JSON responses promptly.
- User authentication means offering signing-up and signing-in functionality to the web and mobile applications. It also involves providing options to authenticate users via their social profiles as on Twitter, Amazon, Facebook, and so on.
- Here, the database could ideally mean a fully-managed NoSQL database, although there is no specific condition for it.
- A Security Token Service [STS] generates temporary credentials, i.e., secret key and API key, for the application users who then use the temporary credentials to invoke the API.
Serverless architecture vs. traditional architecture: the difference
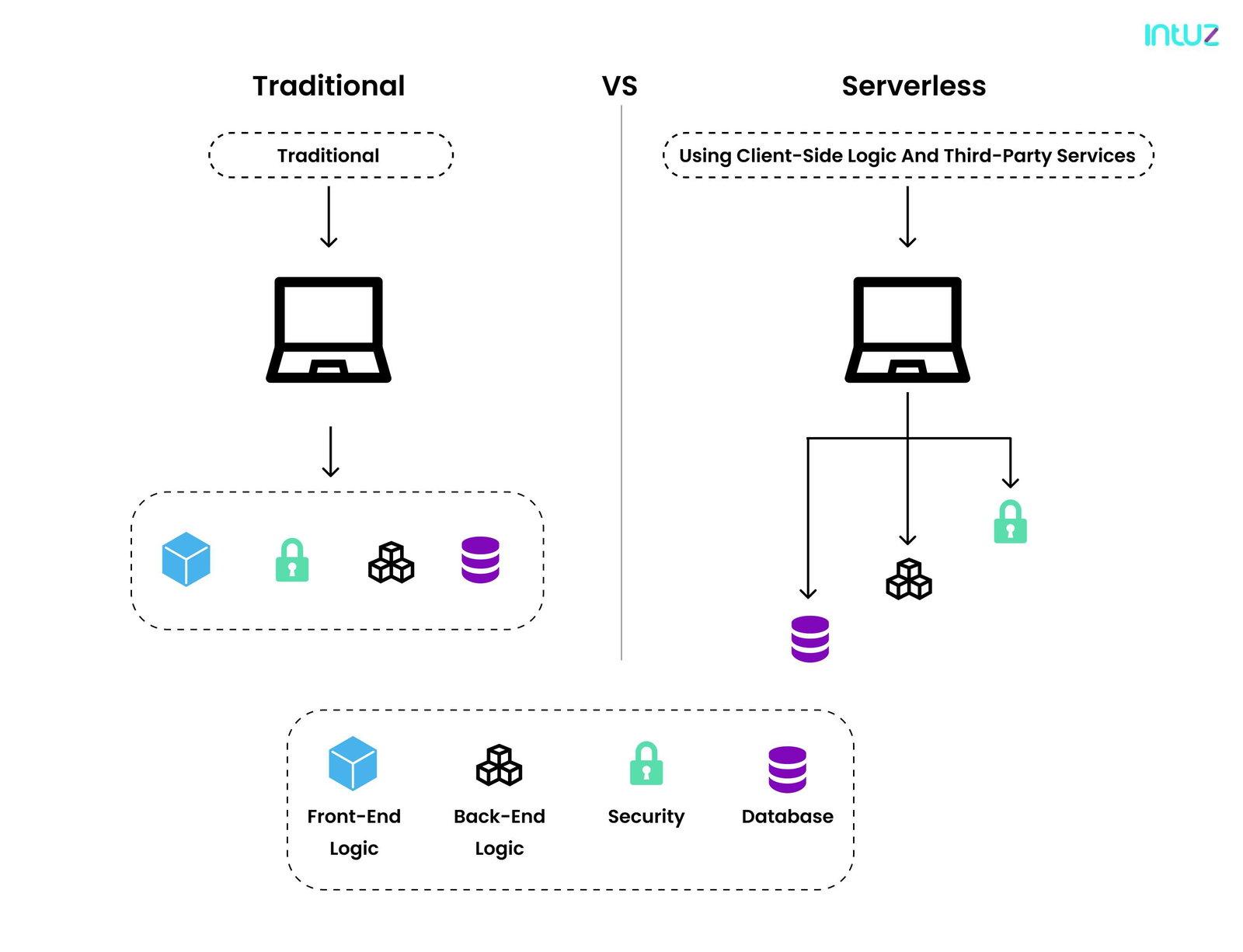
Serverless computing services are different as compared to traditional architecture. The former has breathed new life into how the developers execute code in response to events, leaving behind the complexities of infrastructure managementIn the next section, we draw a comparison between the old and new techniques:

What is Function-as-a-Server [FaaS]?
The “serverless” approach to digital transformation is driven by the need for greater agility and scalability. To keep up with the competition, businesses are always under pressure to quickly update their serverless stack so that their software applications stand out in the market.
For many years, they resorted to monolithic architecture, which was the traditional unified model for designing a software application. However, with time, technologies evolved, and came the time of going serverless.
The serverless computing model offers much respite to the developers as it can provide faster, more efficient, and flexible development services to deliver applications.
Moreover, serverless is focused on any service category, such as database, API gateways, storage, and so on, where billing, management, and configuration are invisible to the end-user.
FaaS, on the other hand, is a type of cloud computing service that allows developers to execute code in response to events without worrying about the complex infrastructure generally associated with building and launching microservice applications.
The common belief is serverless, and FaaS are often conflated with each other. However, the truth is FaaS is a subset of serverless. It is considered the most central technology in serverless architectures wherein the application code or containers run only in response to requests.
Principles of FaaS
There are several principles that developers must follow to make using FaaS easier to deploy and more effective. Here are the top three:

1. Enable each function to perform only one action
Since FaaS is based on “serverless,” it is necessary that each FaaS function is designed to be responsible for only one chore in response to an event or request.
Having said that, the scope of the codebase should be limited so that the serverless functions are lightweight and are able to load and execute quickly.
2. Include as few libraries as possible in the functions
We indeed said that each function should do only one task. However, having too many functions can slow down the functions and make them harder to scale.
3. Do not make functions call other functions
The value of FaaS lies in the isolation of functions. If too many functions are included in the mix, that will increase deployment costs and also make the foundation of the architecture faulty.
4. Get all the benefits of a robust cloud service
FaaS functions are spread across multiple availability zones from a geography perspective and can thus be deployed across many regions with increasing incremental costs. This makes FaaS an ideal tool for high-load scenarios.
Key properties of FaaS
FaaS is a valuable tool for those developers that want to cost-effectively and efficiently migrate applications to the cloud. Here are eight properties of FaaS that cannot be ignored:

1. Independent and server-side
FaaS is similar to the functions written in programming languages. It includes separate logic units that take input arguments, work on the input, and get back on the result.
2. Event-triggered
Although FaaS functions can be invoked independently, they are typically triggered by events from the cloud, such as new database entries, HTTP requests, or inbound app notifications. That is why FaaS is often considered the element that glues all the cloud services in a cloud environment.
3. Stateless
Because FaaS is a subset of serverless, it is not possible to save a file to disk on executing one function and expect it to be there at the next. Any two versions of the same function can run on two different containers in FaaS.
4. Transitory
FaaS functions are designed to be active only when an event happens, or a request is raised. They finish the task and then shut down again without lingering unused for more extended periods of time. When the action is stopped, the underlying containers are not used.
5. Cost-effective
When FaaS functions are not in use, no server remains idle, no code runs, and of course, no costs are incurred. That means FaaS is cost-effective, especially for scheduled tasks or dynamic workloads. There is a need to pay for the resources only when they are in use.
5. Scalability
Since FaaS utilizes multiple containers, many functions run parallelly to service all incoming requests consistently. That helps the application in running smoothly.
6. Fully managed by a cloud vendor
Any cloud vendor can easily handle faaS - AWS Lambda, Google Cloud Functions, and IBM OpenWhisk are some of the most well-known FaaS solutions. All three support Python, Java, Node.js, .NET Core, and other similar programming languages.
7. Total independence
With FaaS, developers can divide the server into functions and scale up or scale them independently without shaking the entire structure. This property allows the developers to focus on the code app and dramatically reduce the time-to-market.
8. High-volume workload management
FaaS enables the isolation of serverless functions, which makes it a brilliant choice for high-volume and parallel workloads. It is thus used to create backend systems and do activities such as format conversion, data aggregation, data processing, encoding, and so on.
Use cases of FaaS
There is no doubt that FaaS can dramatically boost computing performance. The application developer still writes its server-side logic. Here are three uses of this intelligent technology:
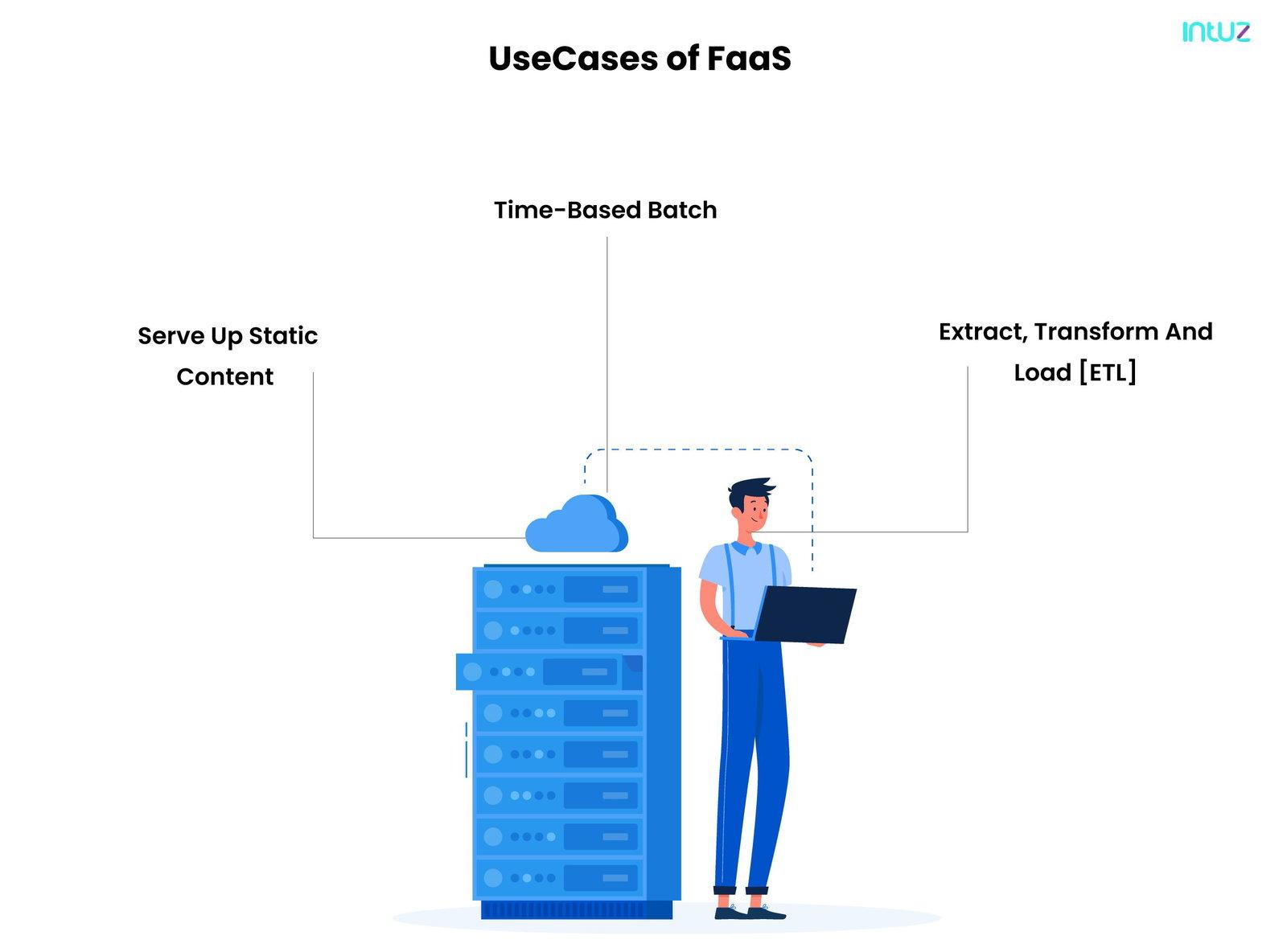
1. Serve up static content
This is by far the most comfortable and most economical use case for serverless computing models. If an application is developed to share static content, it is best to leverage serverless and a dynamic front-end framework to scrape the content directly from the blob. That way, the developer will never have to worry about scaling the server to accommodate the workload.
2. Time-based batch
No business has the budget to keep spending on a ton of licensing fees to keep the infrastructure going. FaaS is created to be active only when an event happens, or a request is raised. When the timer-based functions come to an end, the underlying containers are not used. That means businesses only pay for what is used.
Web apps, data processing, chatbots, IoT devices—all benefit from this use case of FaaS and help developers to keep their costs in check.
3. Extract, Transform and Load [ETL]
Let us say an app takes data from a secure FTP site, transforms some of that data, and loads the data into the database. If the developer is running an expensive SQL compute cycle on the server, it will be time-consuming.
That is why, by leveraging FaaS, it is easy to transform the application to a utility-based model and use functions to only execute and pay for “run instances.”
Understanding serverless microservices: benefits
The term "microservices" is a relatively old term in the world of software architecture. Imagine breaking down an application into small parts, wherein each piece runs independently from other parts of the application and stores its data, and exclusively operates in its environment.
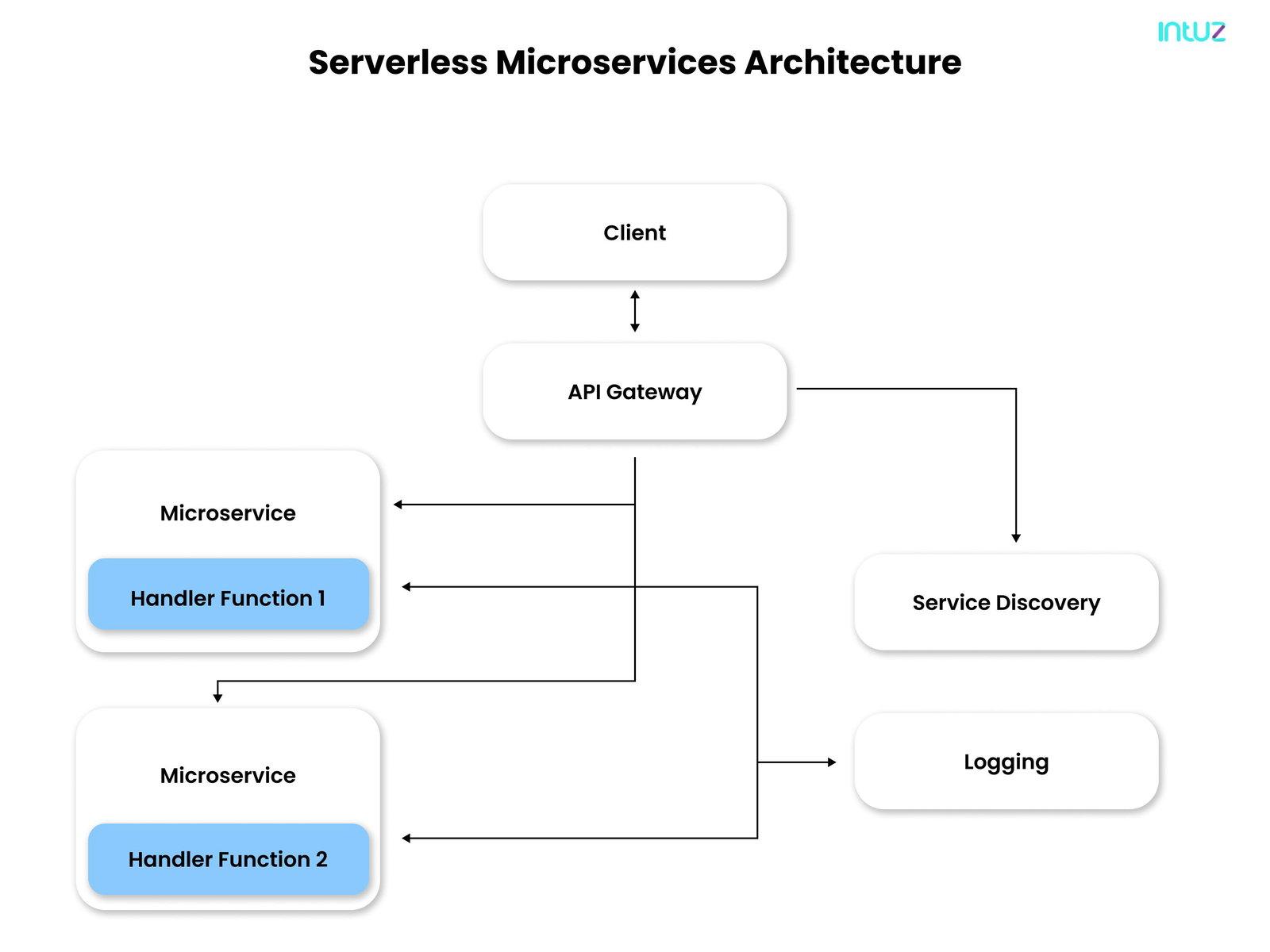
This approach to developing one application as a suite of smaller services is called "microservices." Mind you—despite the name—microservices are not "micro" at all. The word "micro" is merely used to represent handling one service of the more extensive application. Microservices come with a plethora of benefits, some of which include:
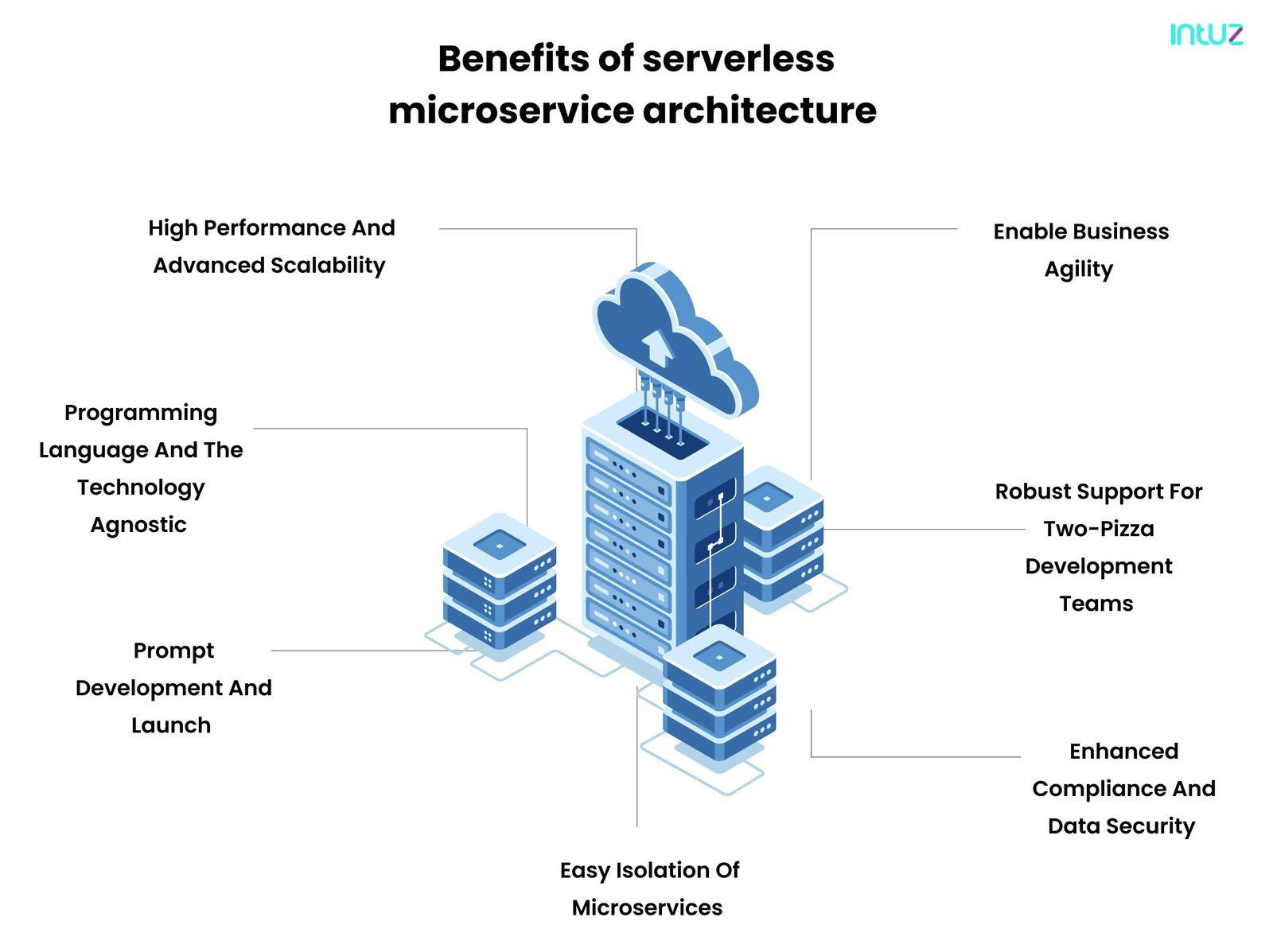
1. High performance and advanced scalability
The microservices' ability to run autonomously makes it relatively easy to scale, add, remove, and update the individual services in their container. That means that if a change happens in microservice A, the other microservices in the application do not get disturbed. Moreover, developers can write individual microservices in different programming languages.
As the app's demand increases, developers can even divert or upgrade several resources to those microservices that have been significantly impacted. When calibrated appropriately, a container orchestration tool can scale each microservice by delegating more processing power. This also helps businesses save money on the cost of the cloud applications.
7 Proven Strategies to Optimize AWS Cloud Cost every organization must know
2. Programming language and the technology agnostic
If developers want to create a microservices-based application, they can do so in any programming language. Moreover, they can also connect with multiple microservices running on any platform. This benefit offers them more flexibility to deploy serverless technologies and use a programming language that best fits their project requirements.
3. Prompt development and launch
The microservices architectural style enables more comfortable and faster application development and up-gradation. The developers can quickly change or build microservices before plugging them into the architecture without worrying about service outages and coding conflicts.
In a nutshell, they can deploy the app's core microservices without worrying about how each service is performing. The same philosophy is applied for updating the app over time - adding serverless technologies as they appear and responding to security threats is more comfortable in individual microservices.
4. Easy isolation of microservices
In this architectural style, the failure of one microservice will not negatively affect other services of the application because of their independent functioning.
However, in larger distributed Microservices architecture, developers have to deal with several dependencies. One way to solve a complete shutdown of the application is by using certain features such as a circuit breaker.
A circuit breaker distracts the server resource from depletion if calling services have to be put on hold. That way, even if a failed microservice shut down, the rest of the application performance will not be hampered.
5. Enhanced compliance and data security
Every microservice incorporates and protects the sensitive data inside it. Despite this fantastic advantage, when the developers establish the data connection between microservices, data breach becomes an issue. That needs to be resolved asap.
Luckily, many developers use APIs to connect with microservices, as the former protects the data by ensuring it is only accessible by specific users, servers, and applications.
6. Robust support for two-pizza development teams
Amazon first brought the "two-pizza" development team rule into the picture. What it meant was to have development teams that were small enough to be fed by the pizzas. That way, it was possible to:
- Improve teamwork and operational efficiency
- Achieve project goals faster
- Build quality applications
- Make team management a breeze
- Enjoy greater focus
7. Enable business agility
Experimenting with new features in the application that may or may not be successful is not considered risky when the microservices architectural style is in the picture. Also, it enables developers to try new features and roll back the changes, provided they do not work out, without hampering the overall performance of the app. The businesses are thus able to enjoy greater agility and keep with customer demands and feedback.
Top five serverless vendors to take note of
Many vendors in the market offer serverless computing services to enable businesses to make their products more efficient, scalable, and agile. So, instead of maintaining their server, a common practice for companies is to invest in the storage space.
But choosing a vendor that specializes in offering a reliable, fast, and safe computing infrastructure can be a challenge. Plus, it is also essential to note the business size, the team’s technical skills, and the app’s scaling ambition.
If choosing the perfect vendor is tricky, let us narrow down the list. Here are the top five serverless vendors to take note of:
1. AWS Lambda

AWS Lambda was first announced at AWS re:Invent in 2014 and is widely considered a stable and mature serverless framework out there in the market. It started with Node.js, but now Lambda also supports C#, Python, and Java.
Today, over a dozen Amazon web services are integrated with Lambda, and the list is only getting bigger. Specifically, Mobile and IoT developers have shown more passion for Lambda because of the power and flexibility it brings to the table.
Besides, the Lambda serverless architecture integrates with Alexa Skills Kit, which is why it is a highly preferred platform for the developers who work on voice-activated applications. It also offers the users an interactive console and command-line tools to upload and manage the snippets with ease.
2. Google Cloud Functions

Google is at the center of the Microservices paradigm. Besides driving the Kubernetes serverless stack, the tech giant has invested in the AWS Lambda competitors such as Cloud Functions, which run on the public cloud infrastructure.
Google Cloud Functions, hosted as containers running on Google Compute Engine, only support Node.js but are expected to add more programming languages to the mix. Only a few Google services such as Google Cloud Storage and Google Cloud Pub/Sub are integrated with it.
It comes with a Stackdriver monitoring system and is limited to 1000 functions with a maximum function duration of 540 seconds.
3. Iron.io

Though it has never projected itself as a serverless computing platform, Iron.io has supported this modern architecture since 2021. Some of its early offerings include IronWorker, IronQueue, and IronCache that encourage developers to bring their codes and run them on the platform with ease.
4. IBM OpenWhisk

IBM OpenWhisk is an open-source platform just like AWS Lambda. Apart from supporting Node.js, it can run snippets written in Swift, and more programming languages are expected to be added to the mix.
The best thing about the framework is that the developers can install it on the local machine running Ubuntu, whereas the Mac OS X and the Windows developers can use the Vagrant box. It is limited to package nesting, which limits the package to contain another package.
5. Microsoft Azure Functions

Microsoft is the latest tech giant to join the long list of Amazon, IBM, and Google in offering the serverless computing platform. It comprises all the required building blocks to assemble the platform promptly and efficiently.
Azure serverless computing platform currently supports languages such as Node.js, F#, C#, PHP, Python, and Java. The third-party language support runs anything with batch files.
Moreover, there are no limits on the maximum execution time, although Azure is limited to only ten concurrent executions per one function.
FAQs
A. Why is RDS not serverless?
Amazon Aurora Serverless is currently the only serverless version offered in RDS. The Aurora database can automatically scale up and scale down based on the usage. For RDS, developers have to choose the type of EC2 instance to run it on.
That means they must think about what virtual server they want underneath and hence, then bill for those instances. With serverless, they do not get to make that choice, which is a drawback.
Besides, the RDS proxy announces handling the connection limits. Rather than managing the functions' connections, the users prefer to offload that to the RDS Proxy. Thus, RDS are not serverless for the users.
B. Why should you not use serverless?
There are three significant instances when you should not use serverless:
- When your workload is constant - Serverless is ideal for running a workload that will fluctuate rapidly in volume. A relatively stable workload, such as a web application where the traffic does not change, is not ideal for serverless. Here, using a dedicated server or a virtual machine is suggested.
- When you want to do advanced monitoring. Since going serverless means using a third-party infrastructure, monitoring and analyzing would not always be possible.
- When you do not want to bind with vendor lock-in - It means you are entirely reliant on a third-party serverless providers and have no control over your application.
C. What are the five components of serverless development?
Five serverless development components include a web server, a FaaS layer, user authentication functionality, a database, and a Security Token Service [STS].
D. What is the significant difference between serverless and traditional architecture?
Serverless is a cloud computing model that enables cloud service providers to manage the servers' allocation dynamically. On the other hand, a traditional server is a large-sized computer accessed over the internet for offering services or information to the end-users.
E. What is a serverless API?
A serverless API is defined by stateless compute containers and modeled for event-driven solutions. The cloud service/ serverless providers fully manages it.
F. Are containers serverless?
No. The two terms, although different, have certain overlapping functionalities in nature. They allow the users to deploy the application code and are more efficient than virtual machines. But both containers and the serverless platform also have several notable differences in terms of hosting environment, costing, and self-servicing ability.
Wrapping it up
Now that you have read the entire guide, one thing is pretty straightforward: adopting serverless architecture has many benefits, but the road to deploying serverless can get challenging for any business if they do not have the right support system to handle it all!
Like any new technological innovation, serverless architecture evolves en route to ensure the services' delivery over time. Serverless architecture may not be the solution to every IT problem. However, it indeed gives us all a sneak peek into the type of computing solutions about to come in the future, and that has got to count for something.
If you need any kind of support regarding serverless for your business, please do not hesitate to drop your requirements on this contact page, and our team will get back to you as soon as possible to help with your requirements.
FAQs
Does serverless mean there are no servers at all?
What are the key benefits of serverless architecture?
How does serverless pricing work?
What is AWS Lambda, and how does it relate to serverless?
What is the difference between FaaS and BaaS in serverless architecture?
What are the main challenges of adopting serverless architecture?
Explore our Web Development Resources
Insights on the latest trends and updates on Web Development


